Roadmap for Infrastructure, Preservation, and Interoperability¶
Introduction¶
As we approach migrations from Digital Commons and Fedora 3, the University of Tennessee Libraries intends to launch two new repository applications: one for digital collections and one for an institutional repository. We intend for both to be built on Hyrax engine and to serve content to and interoperate with a variety of other applications that we as a unit will utilize and invest in.
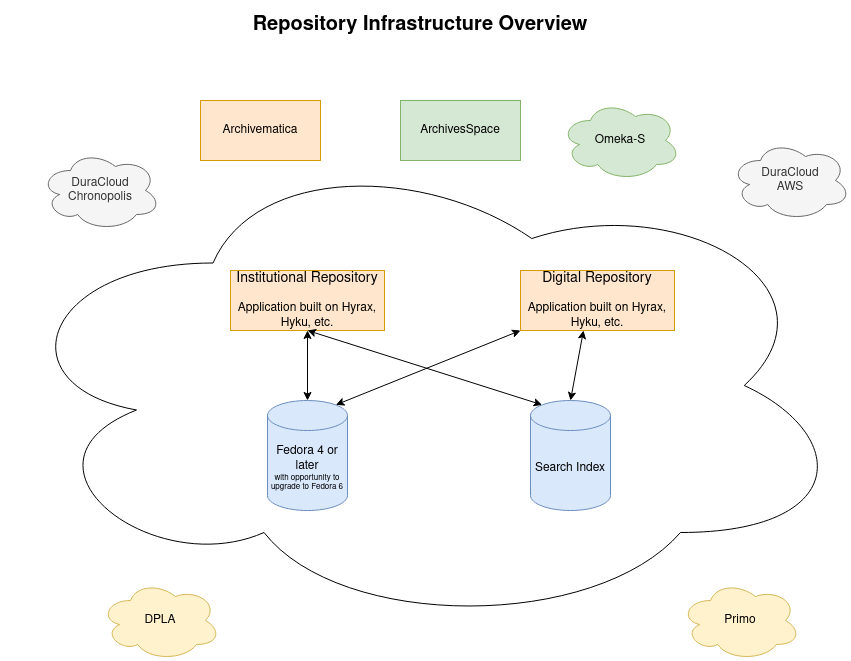
This section describes our current plans and intentions for how our repository applications will interoperate with one another and describes our approach to preservation across systems and hosted services.
Preservation Infrastructure¶
Digital preservation is arguably our unit’s most important responsibility. It is an activity that deserves thoughtful planning to ensure our digital objects are available and secure for perpetuity. As we move towards the future, we have numerous preservation use cases that require our attention: cultural heritage materials from our digital collections, scholarly and creative contributions from our institutional repository, born digital materials that come to special collections from outside donors who likely created files with no plans for longterm preservation, and digital exhibits and other websites that require webarchiving. In order to ensure that these materials will be protected for years to come, we endeavor to use multiple forms of digital preservation activities and several core technologies.

Similar to our current infrastructure, at the heart of our digital assets management and bit-level preservation solution
is Fedora. All our objects and their associated binaries should be managed together with minimal descriptive metadata
and be subject to bit-level preservation. Bit-level preservation is the lowest form of digital preservation and refers
to literally preserving the bits that make up a digital object. As stated in our Digital Preservation Policy Framework,
bit-level preservation activities include maintaining onsite and offsite backup copies, virus checking, periodic
refreshment by copying files to new storage media, and fixity-checking. Instead of Fedora 3 as we currently use, our
next generation service must use Fedora 4 or later with the opportunity to migrate to Fedora 6 as soon as possible.
Fedora 4 or later is important to us for a few reasons. First, Fedora 4, 5, 6 is built on Linked Data Platform. This lets us
store all metadata about a digital object in a fedora:Resource. It then let’s us relate that
fedora:Resource to other resources using Portland Common Data Model.
While Fedora 6 is not a requirement for our next repository in order to go live, having a migration path and plan to
Fedora 6 is a requirement. Fedora 6 is important to us for a few reasons. First, Fedora 6 has much better performance
and scale than Fedora 4 or 5. This is because Fedora 6 drops its’ ModeShape dependency. This techonology has
declined in popularity greatly since Fedora 4 originally launched and is the primary source for performance and scale
issues experienced in Fedora 4 and 5. More importantly, Fedora 6 helps enhance long-term preservation by implementing the
Oxford Common File Layout (OCFL).
OCFL is a simple, non-proprietary, specified, open standards approach to the layout of the preservation persistence
layer in a repository service. It is designed to be file system agnostic and describes how to layout content on whatever
storage media you choose whether it be bare metal or cloud infrastructure. OCFL enhances long-term preservation in
several ways. First, it is built with parseability in mind so that humans can understand the content in a disaster
recovery situtation. This greatly improves our current pair tree infrastructure. Similarly, parseability ensures
machine readability which allows for simple applications to be placed on top of an existing OCFL storage root. Next,
OCFL allows for versioning. This allows for changes to be tracked over time similar to what we do now. OCFL imporves
on versioning by implementing forward delta. Similar to a diff, forward delta allows for just the difference in a
resource to be kept rather than all additional files. This feature will help us greatly with our workflows when writing
to DuraCloud Chronopolis. OCFL is also built with robustness in mind. OCFL is designed to protect your repository
from errors, corruption, and migration between storage media (bare metal to cloud and vice versa). This is because OCFL’s
strong fixity and use of checksums. Content can easiliy be validated using its inventory.json files. Furthermore,
objects are completely self contained. This means that everything a human would need to understand a digital object and
its relationships is stored in the OCFL object. Finally, OCFL is focused on completeness and is designed to ensure
that a repository can be completely restored by reading in content according to OCFL format and its inventory files.
Unlike Trusted Digital Repositories (ISO 16363), NDSA Levels of Preservation, and Open Archival Information Systems
(OAIS), OCFL does not simply talk about what repositories should do, but what the repository will do.
We want to ensure that our fedora:Resources / OCFL objects are available for perpetuity regardless of
what happens to our digital library program, applications, or university. For that reason, we want to deposit our objects
in a dark archive. For us, this is DuraCloud Chronopolis. We only deposit “preservation” objects there. Any proxies or
derivatives related to the object are not stored there.
Last year, a working group between Special Collections and Digital Initiatives wrote TOWARD A BORN-DIGITAL PRESERVATION PROGRAM AT UNIVERSITY OF TENNESSEE LIBRARIES. This document describes the needs of Special Collections in order to launch a born digital program. It ultimately led us to select Archivematica as a solution for more active preservation needs. By active preservation, we mostly mean the ability to migrate files when we were not the creators and long-term preservation was not likely in the mind of the creator. In the system, an archivist ingests a born digital item and an AIP and a DIP is generated. The archivist would also write and acquisition and finding aid in ArchivesSpace. Ultimately, the AIP and DIP should be deposited in Fedora and ultimately DuraCloud Chronopolis. The DIP should also be managed by Fedora and made available for access in applications like ArchivesSpace.
Currently, our plans are to support two DuraCloud solutions: one for dark archiving and one for “dim” archiving. The dark archiving solution, Chronopolis, is for preservation objects only and for materials that are done and meet our requirements for dark archiving. The “dim” archiving solution, DuraCloud AWS, is for objects that are worth of longterm preservation but are not finished and ready for dark archiving. For instance, if a preservation object is likely to change or we have no way of knowing if it may change, we will deposit that object to DuraCloud AWS instead of Chronopolis. Only when something is “done” and “complete” from a preservation standard should it be deposited in Chronopolis.
Finally, Digital Initiatives is interested in developing a web archiving service. While we are still in the early planning stages, we are currently planning to use Heritrix for WARC generation and adding those objects to our Fedora repository for delivery and bit level preservation. No decisions have been made on how WARCs will be emulated.
Interoperability Between Services¶
While ensuring preservation of and providing access to our digital objects is of upmost importance, we also need to
seve these objects to other technologies. As we move towards a new repository system, we plans to focus on a few
standards and services for interoperability. Longterm, we intend for IIIF and its various specifications to be
the focus for interoperability. Because some of the IIIF specifications are still in their infancy, we will use OAI-PMH
to a limited extent in the short term. The diagram below describes this:

We see IIIF and its specifications as the future for how we provide interoperability between our services. In
the diagram above, two IIIF specifications are mentioned specifically: the IIIF Image API and the
IIIF Presentation API. The IIIF Image API transforms images on the server and allows users of clients to
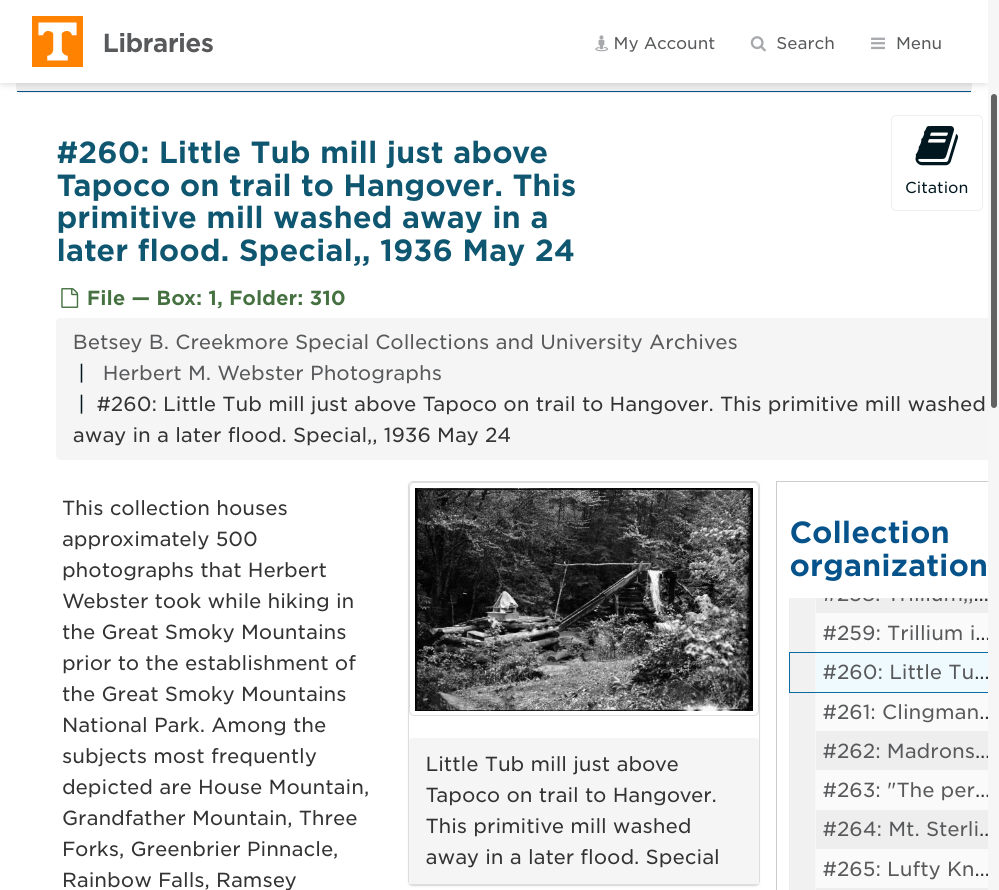
only get what they need. A potential use case for this is linking digital objects in a finding aid in ArchivesSpace to
a digital object in a repository service. To help users get a brief view of what this may be, an image can be generated
on the fly in ArchivesSpace using the IIIF API:
In addition to the image api, we see the IIIF Presentation API as the primary way we will serve digital objects
between systems to meet a variety of user and client needs. The IIIF Presentation API allows us to create recipes
for different content models and use cases so that our content can be served in viewers in ways that best fit our needs.
In order to think about serving content across different systems with the IIIF Presentation API, UT Libraries
Digital Initiatives maintains a UTK IIIF Cookbook. Here is an
example of an “embedded recipe” for thinking about serving our oral histories:
The sample manifest can be found here.
While we intend to use OAI-PMH for the time being, we view it as a legacy technology that we will eventually
abandon. Instead, we believe that the IIIF Change Discovery API is how we will
eventually find and share metadata and the objects that the metadata represents between services. We recognize that the
API is in beta and not stable enough to develop against, we feel strongly that this is where we and other libraries will
eventually implement for sharing.
While we see IIIF as our future and plan to focus on it heavily, we realize that we are still in
need of OAI-PMH for the near future. This technology is what we use to serve metadata to our aggregation service
and on to services such as DPLA, tn.dp.la, and our Ex Libris Primo instance. While the technology is very old, we
it is what our current external services rely on. While it would be possible to move away from it entirely, it would be
expensive to do so at this time. For instance, if we moved away from OAI-PMH for DPLA, it would require DPLA to rewrite
all normalization and this task would be entirely outside our control. Similarly, while other solutions exist for Ex
Libris Primo for external discovery import profiles, these have never been explored or implemented here and would require
reenvisioning and a total reimplementation of workflows.